NO.63 An API implementation is being designed that must invoke an Order API which is known to repeatedly experience downtime. For this reason a fallback API is to be called when the Order API is unavailable. What approach to designing invocation of the fallback API provides the best resilience?
* Resilience testing is a type of software testing that observes how applications act under stress. It’s meant to ensure the product’s ability to perform in chaotic conditions without a loss of core functions or data; it ensures a quick recovery after unforeseen, uncontrollable events.
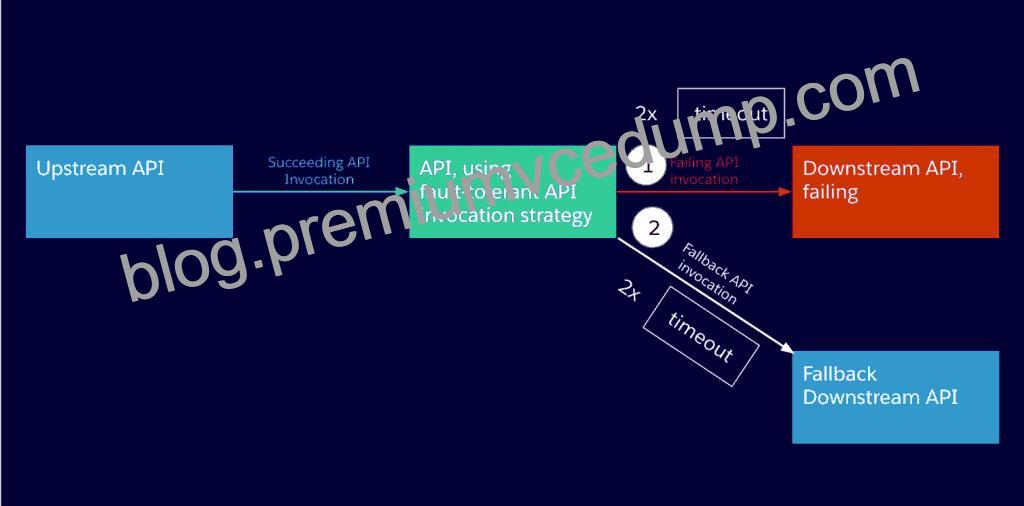
* In case an API invocation fails – even after a certain number of retries – it might be adequate to invoke a different API as a fallback. A fallback API, by definition, will never be ideal for the purpose of the API client, otherwise it would be the primary API.
* Here are some examples for fallback APIs:
– An old, deprecated version of the same API.
– An alternative endpoint of the same API and version (e.g. API in another CloudHub region).
– An API doing more than required, and therefore not as performant as the primary API.
– An API doing less than required and therefore forcing the API Client to offer a degraded service, which is still better than no service at all.
* API clients implemented as Mule applications offer the ‘Until Successful Scope and Exception’ strategies at their disposal, which together allow configuring fallback actions such as a fallback API invocation.
* All HTTP response status codes within the 3xx category are considered redirection messages. These codes indicate to the user agent (i.e. your web browser) that an additional action is required in order to complete the request and access the desired resource
Hence correct answer is Redirect client requests through an HTTP 303 temporary redirect status code to the fallback API whenever the Order API is unavailable